 yyhh.org
yyhh.org 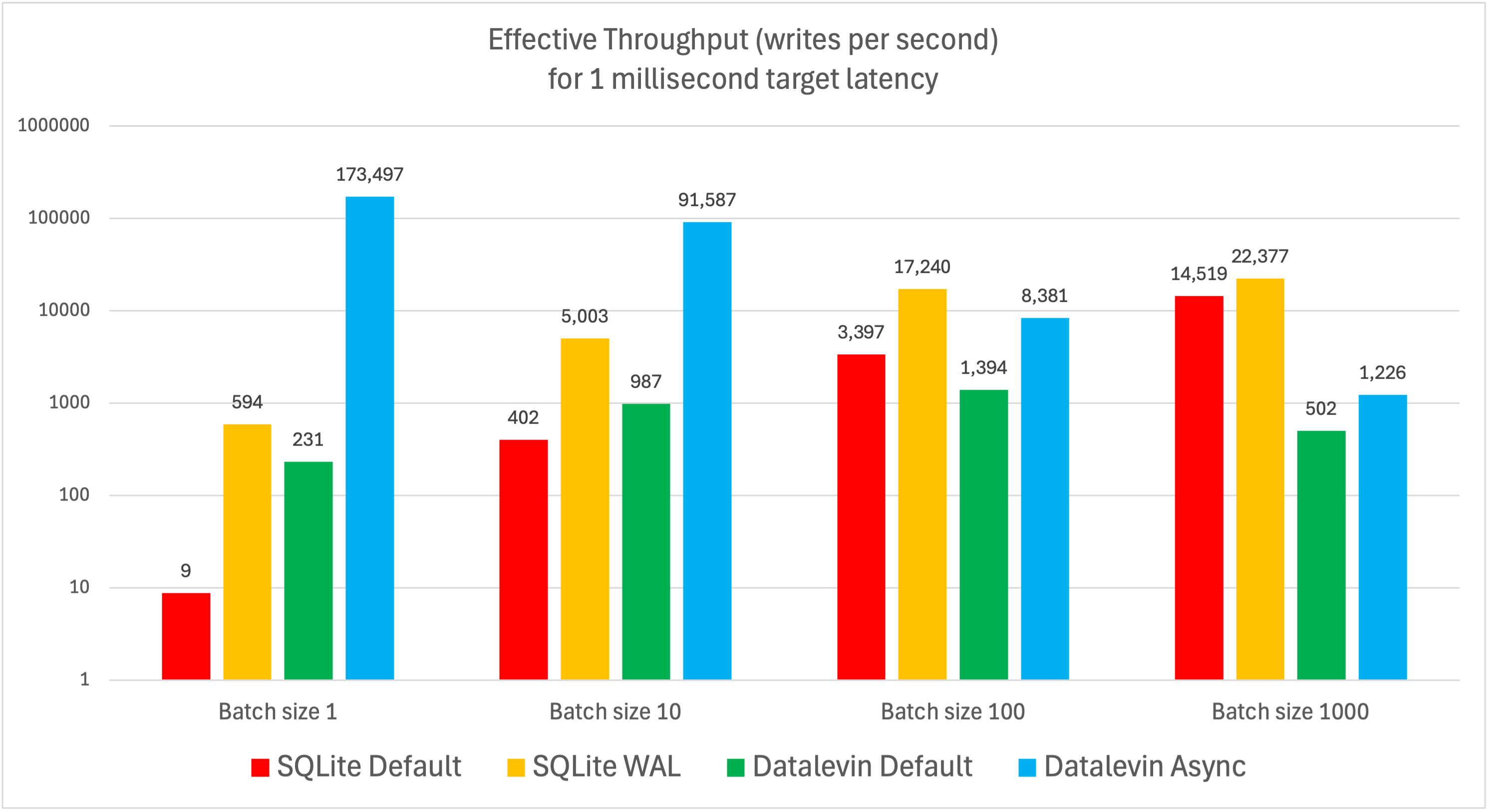
In my previous post, I demonstrated that Datalevin performs complex queries faster than PostgreSQL. A common reaction is, "Oh, have you tested writing speed? I imagine that when there are indices for everything (as in the case of Datalevin), writing speed could be significantly slower." This post aims to address that write speed concern.
When discussing database write speed, throughput and latency are the two key performance metrics. Throughput is the number of transactions the system can process in a given amount of time—the higher the throughput, the better the system. Latency is the amount of time it takes to process a single transaction from start to finish. In durable databases, this refers to the time between when the transaction starts and when the data is committed and flushed to disk. The lower the latency, the better the system performs.
Obviously, it is desirable to have both high throughput and low latency. However, achieving both simultaneously is often challenging.
Throughput-Latency Trade-Off
To improve throughput, database systems often use batching techniques (grouping many transactions together) to amortize the setup cost across multiple transactions. In particular, the number of expensive disk flush operations can be reduced dramatically through batching. However, waiting to accumulate a batch may increase the latency for individual transactions.
Conversely, processing transactions immediately reduces the wait time for each transaction, lowering latency. Yet handling each transaction independently can prevent the system from fully utilizing available resources, potentially resulting in lower overall throughput.
Asynchronous Transaction
A well-implemented asynchronous transaction model has the potential to improve both throughput and latency simultaneously. Instead of processing a transaction immediately, an asynchronous transaction is placed in a queue—this provides an opportunity to batch it with other transactions, thereby improving overall throughput. Of course, it is still important to ensure that transactions do not wait too long in the queue, which could hurt latency.
Some databases implement asynchronous commit. For example, PostgreSQL’s
synchronous_commit parameter can be set to off. In this mode, the system
returns transaction success as soon as the transaction is logically
completed—before the generated WAL (Write-Ahead Log) records are actually
written to disk. However, this implementation compromises durability and
consistency guarantees. There is a short window between reporting transaction
completion and when the transaction is truly committed. If the system crashes
during this risk window, the changes made by that transaction may be lost.
PostgreSQL allows users to control the duration of this risk window by setting
wal_writer_delay.
Adaptive Asynchronous Transaction
Striking a balance between the advantages of asynchronous processing and the durability guarantees of transactions might seem challenging. In Datalevin, we aim to take advantage of asynchronous transactions without compromising durability. Moreover, having too many tuning parameters goes against our goal of excellent database usability—there is really no good reason for a user to worry about such low-level implementation details.
To achieve these goals, I have implemented an adaptive asynchronous transaction method in Datalevin.
The idea is as follows. First, to maintain transaction durability, the
asynchronous transaction method returns a Clojure future, which is only realized
once the transaction is fully committed and the data is flushed to disk. The
user can dereference the future to determine when the transaction is completed,
or block until it is. Alternatively, the method optionally accepts a
user-supplied callback function so that the user can be notified when the
transaction is complete.
At first glance, these options might seem no different from a synchronous transaction: the user still has to wait until the commit is completed. However, the promise of asynchronous transactions is this: the wait will be shorter than with synchronous transactions. If we can achieve a shorter wait time, we have succeeded.
How can we achieve a shorter wait time? As suggested above, one answer lies in batching transactions.
The challenge now is to find an appropriate batch size that minimizes wait time. As argued earlier, setting a fixed batch size or preset time delay isn’t ideal. Instead, the batch size—or equivalently, the wait time in the queue—should depend on the system load.
When the system is inundated with write requests, a larger batch size is useful for dispatching many requests at once, thus improving throughput. On the other hand, when the system is idle, a write request should be fulfilled immediately, thus minimizing latency. In other words, we want a dynamic batch size that adapts to system load.
Another source of reduced wait time is improved concurrency. While waiting for an I/O operation to complete, other tasks can use the CPU. Proper design allows this overlapping of computation and I/O to effectively “hide” I/O wait times.
The most direct way to achieve this is through a simple mechanism [1]: when processing a queued asynchronous write event, the system checks its event queue to see if there are other similar events waiting. If so, the system simply ignores the duplicate event and moves on to the next one. Otherwise, it submits a task to a worker thread pool to process the queued asynchronous transactions in a batch.
This mechanism exhibits the adaptive behavior described above. Under a heavy load, the batch size increases; when the load is low, the batch size is small. The available system resources are effectively utilized to optimize both throughput and latency outcomes—without compromising durability.
Metric
In order to measure how well we have achieved our goal, we need a metric that combines throughput and latency. Combining these two metrics into a single number is challenging because they measure different aspects of performance and have different units. There may not be a perfect answer, but here are a few ideas.
One simple composite is to compute a ratio such as Throughput / Latency. A
higher value implies that the system is processing more transactions quickly
(i.e., achieving high throughput and low latency). However, if throughput is
measured in transactions per second and latency in seconds per transaction, the
ratio has units of transactions squared per second, which makes its
interpretation less obvious.
One way to refine this formula is to introduce a target latency required by a particular use case. For example, for low-latency applications that expect sub-millisecond database transactions, the target latency might be 1 millisecond. For applications that can tolerate slightly higher latency, the target might be 10 milliseconds.
With a target latency in place, we can define an effective “good throughput” for a given use case. One simple approach is to combine throughput with the fraction of operations finishing within that target latency. For instance, one might define a metric like this:
Effective Throughput = Actual Throughput × (Target Latency / Actual Latency)
This metric rewards systems that process many transactions and keep them within acceptable latency boundaries. If the latency exceeds the target, the effective throughput metric drops, reflecting a degraded user experience.
Effective Throughput (ET) is a use-case–dependent metric that is simple to
interpret. The higher the ET, the better the system. It is also easy to
calculate, as its value is proportional to the target latency. For example, the
ET for a 10-millisecond target is 10 times that for a 1-millisecond target.
Thus, we really only need to calculate the ratio of throughput to latency (i.e.,
for a target latency of 1 unit) and then extrapolate to other target latencies.
For the analysis below, we will adopt ET.
Benchmark
To address the write-speed concerns of Datalevin, we compare Datalevin with SQLite—the most widely used embedded database, renowned for its fast writes. Although Datalevin can be used in a client/server mode, for this benchmark we use it as an embedded database.
Using the same dataset, we compare four transaction conditions: Datalevin
Default, Datalevin Async, SQLite Default, and SQLite WAL. These are all fully
durable transaction methods—a transaction is considered complete only after its
data is fully flushed to disk.
Database transaction benchmark performance is highly sensitive to hardware and the operating system; the numbers can vary widely between different machines. In this benchmark run, we used a machine with a 2016 Intel Core i7-6850K CPU @ 3.60GHz (6 cores), 64GB RAM, and a Samsung 860 EVO 1TB SSD. This machine performs around the middle of the pack in Today's CPU Benchmark, so it is reasonably representative.
The code and detailed description of the benchmark can be found in our GitHub repository.
Pure Write
The benchmark has two tasks. The first is a pure write task, where each write consists of an entity (row) with two attributes (columns). Every 10,000 writes, we measure the throughput and latency. In addition to individual writes, we also measure performance when writing data in batches—testing batch sizes of 10, 100, and 1000.
Using the Effective Throughput (ET) metric described above, the bar chart at the
top of this post shows the pure write task results. (Note: the Y axis is
logarithmic.)
When the batch size is 1 (i.e., writing a single entity at a time), Datalevin
Async achieves the best ET. It is several orders of magnitude higher than under
other write conditions—not only is the raw throughput high (16,829.2 writes per
second), the latency is low (0.1 milliseconds) as well. When writes are batched,
the ET of Datalevin Async slightly decreases due to the latency increasing
faster than throughput.
Datalevin Default performance peaks at a batch size of 100; however, at that
batch size, SQLite’s performance outperforms it.
SQLite Default performs very poorly for individual writes, though SQLite WAL is
much better. Both benefit significantly from increased batch sizes, with SQLite
Default benefiting the most.
In general, Datalevin's write performance is more stable and less sensitive to variations in batch size compared to SQLite. Because Datalevin performs indexing at transaction time, its write performance does not benefit as much from increased batch sizes.
For an operational database, each transaction normally contains a small number of entities (or rows), as recommended by industry best practices [2]. In these online transaction processing (OLTP) workloads, Datalevin is expected to perform better than SQLite.
For use cases involving the bulk loading of data, Datalevin provides init-db and
fill-db functions that bypass the expensive transactional processes and are more
appropriate.
Mixed Read/Write
After one million entities (rows) have been loaded, the second task alternates
between reading a row and writing a row until one million reads and one million
writes have been performed. For this task, we report the results using Linux’s
time command.
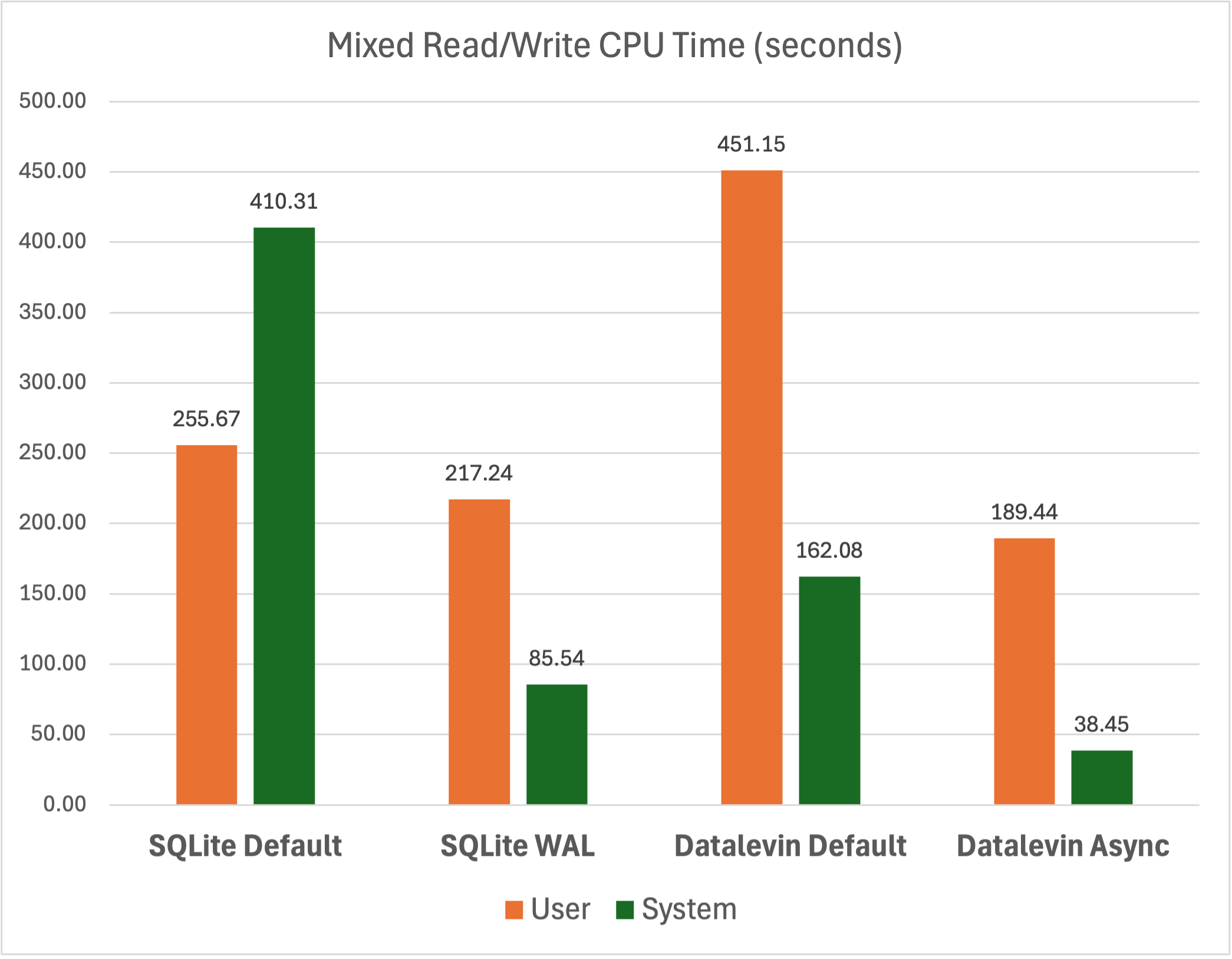
The first chart shows wallclock time, while the second shows user and system CPU time.
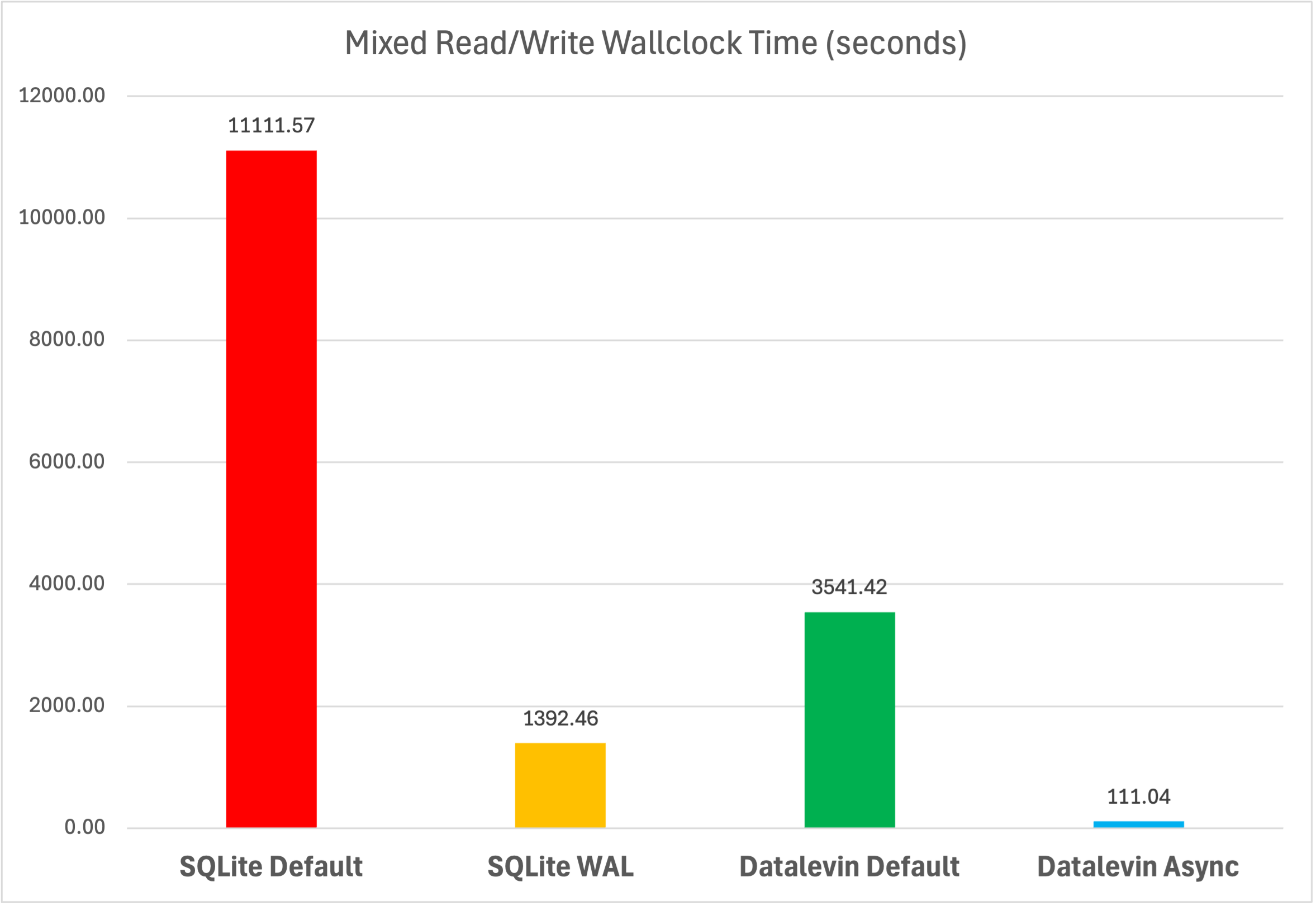
For the mixed read/write task, Datalevin Default is much faster than SQLite
Default, and Datalevin Async is much faster than SQLite WAL, while SQLite
WAL outperforms Datalevin Default.
Regarding CPU time, the differences among the various conditions are small, indicating that the underlying amount of work is not hugely different.
Notice that in the three synchronous conditions—Datalevin Default, SQLite
Default, and SQLite WAL—most of the time is spent waiting for I/O, with CPU
times being relatively small compared to the wallclock time. Datalevin Async
is different; its total CPU time (227.89 seconds) is actually greater than its
wallclock time (111.04 seconds), indicating effective utilization of multicore
processing and an apparent hiding of I/O wait times. This result confirms our
hypothesized advantage of asynchronous transactions.
Conclusion
We can now answer the question about Datalevin's write speed: it performs better than SQLite under OLTP workloads. While the default synchronous write mode performs at a respectable level, Datalevin truly shines with asynchronous transactions, achieving both high throughput and low latency without compromising transaction durability.
Reference
[1] Nathan Marz, "2.5x Better Performance: Rama vs. MongoDB and Cassandra", April 2024. (https://blog.redplanetlabs.com/2024/04/25/better-performance-rama-vs-mongodb-and-cassandra/)
[2] Gray, J., & Reuter, A. Transaction Processing: Concepts and Techniques. Morgan Kaufmann Publishers, 1993.
Comments
comments powered by Disqus